前言
这是一道验证码题目,比较难,下面我们来尝试解决他
思路
观察网络请求
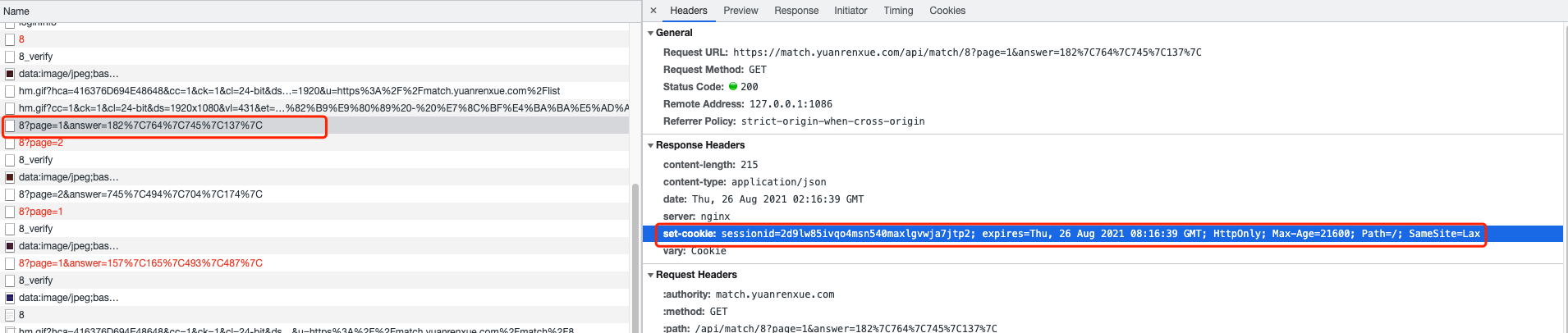
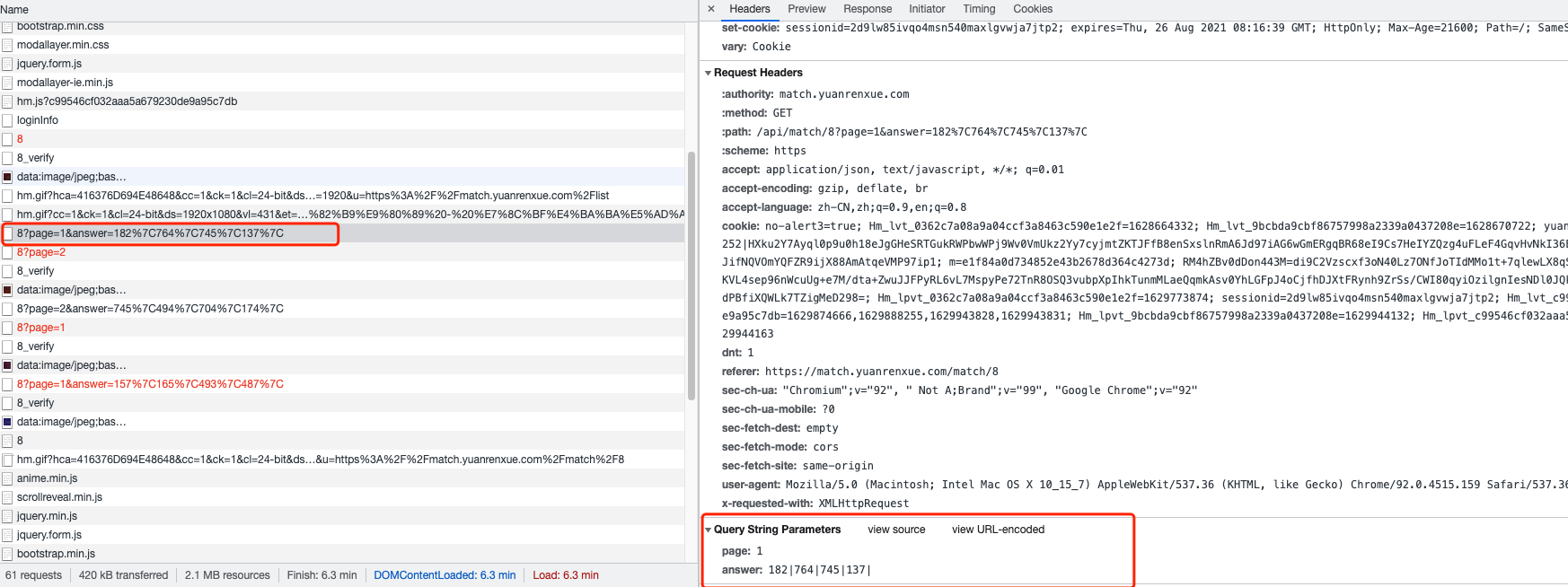

可以看出是需要提交answer正确参数,并携带正确的set-cookie才能得到数据
继续向上查看请求

这里返回html 里面有需要点击的参数名字和base64图片的img
打开是这样

发送请求answer的真实含义
断点看下变量生成过程

原来如此
将整张图片分为30*30个div。每个字就为10**10个div然后点哪就携带那的坐标点
比如横向前四个div就为0|1|2|3
做个假设
那么我们记录每个图片的中心点坐标。分别对应0,1,,3,4,5,6,7,8
map_dict = {
'0': 155,
'1': 166,
'2': 175,
'3': 456,
'4': 436,
'5': 446,
'6': 725,
'7': 766,
'8': 776,
}最后思路
- 识别每张图片对应的字依次放进数组, 从左到右,从上到下
- 知道要选取的字
- 每个字对应图片数组的下标
- 每个图片数组下标对应的中心坐标
结果惨淡
这中文识别如果不是自己会去训练真的识别不了。尝试了百度中文识别、讯飞、腾讯最后都败下阵来
github上东西也搞不定。说明作者就是让我们做机器识别。但无奈不会啊。怎么办
换一种思路
既然识别不了。那么就手动识别怎么样呢?当然这是一种取巧方式,也不建议这样做,还是老实学机器学习吧
我们知道图片。也知道什么字。只需要填入0123456789即可
答案解答
python 代码
# coding: utf-8
# author: QCL
# software: PyCharm Professional Edition 2018.2.8
import re
import cv2
import base64
import requests
import numpy as np
from collections import Counter
from urllib.parse import urlencode
SUM_TOTAL_LIST = []
CHARACTERS_NUM_MAP = {
'1': 155,
'2': 166,
'3': 175,
'4': 456,
'5': 436,
'6': 446,
'7': 725,
'8': 766,
'9': 776,
}
def get_click_characters_and_image(session, page):
image_url = 'http://match.yuanrenxue.com/api/match/8_verify'
with session.get(url=image_url) as response:
if response.status_code == 200:
image_pattern = re.compile(r'<img src=.*?base64,(.*?)\" alt=', re.S)
click_characters_pattern = re.compile(r'<p>(.*?)</p>', re.S)
click_unicode_characters = re.findall(click_characters_pattern, response.text)
click_characters = list(map(lambda x: x.encode('utf-8').decode('unicode-escape'), click_unicode_characters))
image_base64_str = image_pattern.findall(response.text)[0] if image_pattern.findall(response.text) else ''
if image_base64_str:
with open(f'{page}_origin.png', 'wb') as f:
f.write(base64.b64decode(image_base64_str))
return click_characters
def handle_image(page):
"""
图片干扰处理这块 ---> 借鉴来自Java_S大佬
url详解地址:https://syjun.vip/archives/284.html
大佬本人此项目地址为:Java-S12138/yuanrenxue_python_spider
"""
# cv2.imread读取图像
im = cv2.imread(f'{page}_origin.png')
# img.shape可以获得图像的形状,返回值是一个包含行数,列数,通道数的元组 (100, 100, 3)
h, w = im.shape[0:2]
# 去掉黑椒点的图像
# np.all()函数用于判断整个数组中的元素的值是否全部满足条件,如果满足条件返回True,否则返回False
im[np.all(im == [0, 0, 0], axis=-1)] = (255, 255, 255)
# reshape:展平成n行3列的二维数组
# np.unique()该函数是去除数组中的重复数字,并进行排序之后输出
colors, counts = np.unique(np.array(im).reshape(-1, 3), axis=0, return_counts=True)
# 筛选出现次数在500~2200次的像素点
# 通过后面的操作就可以移除背景中的噪点
info_dict = {counts[i]: colors[i].tolist() for i, v in enumerate(counts) if 500 < int(v) < 2200}
# 移除了背景的图片
remove_background_rgbs = info_dict.values()
mask = np.zeros((h, w, 3), np.uint8) + 255 # 生成一个全是白色的图片
# 通过循环将不是噪点的像素,赋值给一个白色的图片,最后到达移除背景图片的效果
for rgb in remove_background_rgbs:
mask[np.all(im == rgb, axis=-1)] = im[np.all(im == rgb, axis=-1)]
# cv2.imshow("Image with background removed", mask) # 移除了背景的图片
# 去掉线条,全部像素黑白化
line_list = [] # 首先创建一个空列表,用来存放出现在间隔当中的像素点
# 两个for循环,遍历9000次
for y in range(h):
for x in range(w):
tmp = mask[x, y].tolist()
if tmp != [0, 0, 0]:
if 110 < y < 120 or 210 < y < 220:
line_list.append(tmp)
if 100 < x < 110 or 200 < x < 210:
line_list.append(tmp)
remove_line_rgbs = np.unique(np.array(line_list).reshape(-1, 3), axis=0)
for rgb in remove_line_rgbs:
mask[np.all(mask == rgb, axis=-1)] = [255, 255, 255]
# np.any()函数用于判断整个数组中的元素至少有一个满足条件就返回True,否则返回False。
mask[np.any(mask != [255, 255, 255], axis=-1)] = [0, 0, 0]
# cv2.imshow("Image with lines removed", mask) # 移除了线条的图片
# 腐蚀
# 卷积核涉及到python形态学处理的知识,感兴趣的可以自行百度
# 生成一个2行三列数值全为1的二维数字,作为腐蚀操作中的卷积核
kernel = np.ones((2, 3), 'uint8')
erode_img = cv2.erode(mask, kernel, cv2.BORDER_REFLECT, iterations=2)
cv2.imshow('Eroded Image', erode_img)
cv2.waitKey(0)
# cv2.destroyAllWindows()可以轻易删除任何我们建立的窗口,括号内输入想删除的窗口名
cv2.destroyAllWindows()
cv2.imwrite(f'{page}_handle.png', erode_img)
def get_one_page(session, page):
click_characters = get_click_characters_and_image(session, page)
print(click_characters)
# 处理图片
handle_image(page)
nums = input('请在处理后的图片中依次输入文字占位号:')
temp_list = []
for num in nums:
temp_list.append(str(CHARACTERS_NUM_MAP.get(num)))
query_string = {
'page': page,
'answer': '|'.join(temp_list) + '|'
}
dst_url = 'http://match.yuanrenxue.com/api/match/8?' + urlencode(query_string)
with session.get(url=dst_url) as response:
if response.status_code == 200:
res = response.json()
if 'data' in res.keys() and res.get('data'):
print(f'第{page}页数据为:', res.get('data'))
for item in res.get('data'):
SUM_TOTAL_LIST.append(item.get('value'))
def most_common():
d = {}
for i in SUM_TOTAL_LIST:
d[i] = d.get(i, 0) + 1
ret = []
n = None
for j in sorted(d.items(), reverse=True, key=lambda x: x[1]):
if len(ret) == 0:
ret.append(j[0])
n = j[1]
else:
if j[1] == n:
ret.append(j[0])
else:
break
return ret
def main():
session = requests.Session()
headers = {
'Host': 'match.yuanrenxue.com',
'Referer': 'http://match.yuanrenxue.com/match/8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/88.0.4324.104 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
session.headers = headers
for page in range(1, 6):
if page < 4:
get_one_page(session, page)
else:
session.headers.update({
'User-Agent': 'yuanrenxue.project'
})
get_one_page(session, page)
# break
# 下面方法缺陷:当出现同频率的元素只能返回其中的一个
# print(sorted(Counter(SUM_TOTAL_LIST).items(), key=lambda x: x[1], reverse=True)[0][0])
ret = most_common() # 当出现同频率的元素都会被捕捉到
print(ret)
if __name__ == '__main__':
main()


